ChattyInfty3 AITalk版の操作方法
目次
- 1. 概要
- 2. 準備
- 3. 操作方法
1. 概要
ChattyInfty3 は合成音声付き電子書籍を簡単に作成できるWindowsアプリケーションである。できることは一般的なEPUBエディタより少ないが、操作方法は単純である。 基本的にはワープロのように操作できる。
ChattyInfty3 には AITalk版と SAPI5版がある。 両方とも、間違った読み上げの修正、ポーズの長さの調整、ハイライト分割(ハイライト区切り)位置の調整などの機能があるが、以下の点で違いがある。
| AITalk版 | SAPI5版 |
|---|---|
| 日本語の 読み上げ アクセントを 調整 できる。 | 読み上げ アクセントは 調整 できない。 |
| 日本語と 英語 以外の 言語の 正しい 読み上げが 不可能。 | SAPI5の 合成音声が 存在する 言語なら、 どの 言語でも ほぼ 正しい 読み上げが 可能。 |
| 日本語や 英語で 使われない 文字が 書誌情報に あると 文字化けする。 | UTF-8で 表示できる 文字なら、 日本語や 英語で 使われない 文字でも 文字化け しない。 |
日本語書籍を扱う場合、AITalk版を使うと高品質の読み上げ音声が得られる。 英語以外の外国語を含む場合は SAPI5版を併用するか、他の読み上げエンジンで読ませた音声ファイルを ChattyInfty3 の読み設定で取り込む。 SAPI5版の操作方法は、 AITalk版より機能が少ないだけなので、 AITalk版の使い方を習得すれば SAPI5版の扱いには困らない。
ChattyInfty3のAITalk版の読み上げ調整機能は、AITalk単体より機能制限されているものの、ある程度の調整は可能である。 合成音声の読み間違いや、マのとり方を修正しつつ、自然な読みを損なわないためには、以下の技能が必要になる。
- 意味が正しく伝わらない読みに「気付く耳」
- 録音図書製作の音訳処理に関する知識
- 日本語のアクセント規則についての基礎知識
「気付く耳」の習得には音訳者としての訓練が必要であり、ここでは説明しない。 音訳処理に関する知識については、ここでは説明しない。 日本語のアクセント規則については、操作のための最低限の知識に言及する。 以下の説明は ChattyInfty3 AITalk版 ver.3.25c に基づいているので、それ以降のバージョンに当てはまらない可能性がある。
2. 準備
新規プロジェクトに取り掛かる前に、アプリをアップデートする。
まず手元のバージョンを確認する。Chattyを起動して、ウィンドウの一番上のタイトルバーを見る。
次に ChattyInftyの概要のページを開く。
- 「ChattyInfty3 AITalk4版本体(音声辞書なし)」という欄に、手元のバージョンより新しいものが出ていれば、そのリンクを右クリックして保存。
バージョンアップにより操作方法が変わることもあるので、「更新内容」の pdf も確認する。 - その上の「ChattyInfty3 AITalk4版用音声辞書」の欄も、頻度は低いが更新されることがあるので、新しいものが出ていれば、そのリンクを右クリックして保存。
- もっと下の方にある「ChattyInfty3_SAPI5版」という欄に、手元のバージョンより新しいものが出ていれば、そのリンクを右クリックして保存。
- 更に下にある「全ルビ生成プラグインのダウンロード」という欄に、手元のバージョンより新しいものが出ていれば、そのリンクを2つとも右クリックして保存。
アップデートがある場合には、以上の操作で4個か5個の zip ファイルが自分のパソコン内のフォルダ(デフォルトでは「ダウンロード」という名前のフォルダ)に保存される。 それらの zip ファイルを1つずつ右クリックして展開し、その中にある exe ファイルをダブルクリックしてインストールする。 インストールする順番は、上の手順で保存した順番と同じ。 SAPI5版のインストールのときにimlxファイルの関連付けをするか聞かれるが、しない方に設定する。これはAITalk版の方で関連付けするため。
以上の方法でアップデートに失敗する場合は、すでに入っている Chatty のアプリをアンインストールしてから上記の方法でインストールし直す。
アンインストールするには、Windows 画面左下の虫めがねマークに「アプリと機能」と書いて上に出る「開く」をクリック。 インストールされているアプリの一覧が出るので、その中の「AddRuby for ChattyInfty3…」「AITalk4 Package for ChattyInfty3…」「ChattyInfty3…」といった名前を選択し、「アンインストール」ボタンをクリックする。
英語以外の外国語を読み上げさせる場合
必要な外国語の音声を以下の方法でセットアップする。
スタートメニューから「設定」を開き、その中の「時刻と言語」を開き、左の枠内の「音声認識」をクリック。 右の欄の下の方の「音声の管理」で「音声を追加」という「+」ボタンをクリック。 必要な音声を選んで「追加」ボタンをクリック。 インストールが終わると、その言語の音声が Chatty で利用できる。
男声を利用したい場合は、更に Speech Five Magic をダウンロードし、展開して実行する。 このアプリがデバイスに変更を加えることを許可する。 必要な音声のチェックボックスをオンにして Apply ボタンをクリックする。
3. 操作方法
3.1. ChattyInfty3 の編集画面
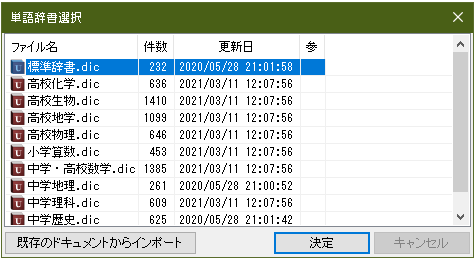
ChattyInfty3 AITalk版を起動すると、まず単語辞書選択ウィンドウが出る。一般には 標準辞書.dic を選択して決定する。学校教科のデイジー図書を作る場合は適切な教科の辞書をリストから選んで決定する。
単語辞書を後で選び直したいときは、メニューの「設定>単語辞書を変更」によって変更できる。ただし、変更すると、自分で登録した単語も消えてしまう。あらかじめ、自分で登録した単語を含む Chatty ファイル *.imlx を別名で保存しておくと、単語辞書変更後に「設定>単語辞書をインポート」することによって、自分で登録した単語を取り戻すことができる。
Chatty メイン画面の右の欄は文書編集領域である。ここでワープロと同様に文章を編集できる。ワードなどの他のアプリの文書を開いて、そこからコピーして貼り付けることもできる。
左の欄はセクションのリストになる。たくさんのセクションがあるときは、1つのセクションを選ぶと、そのセクション内容が右の欄の編集領域に表示されて編集できる。
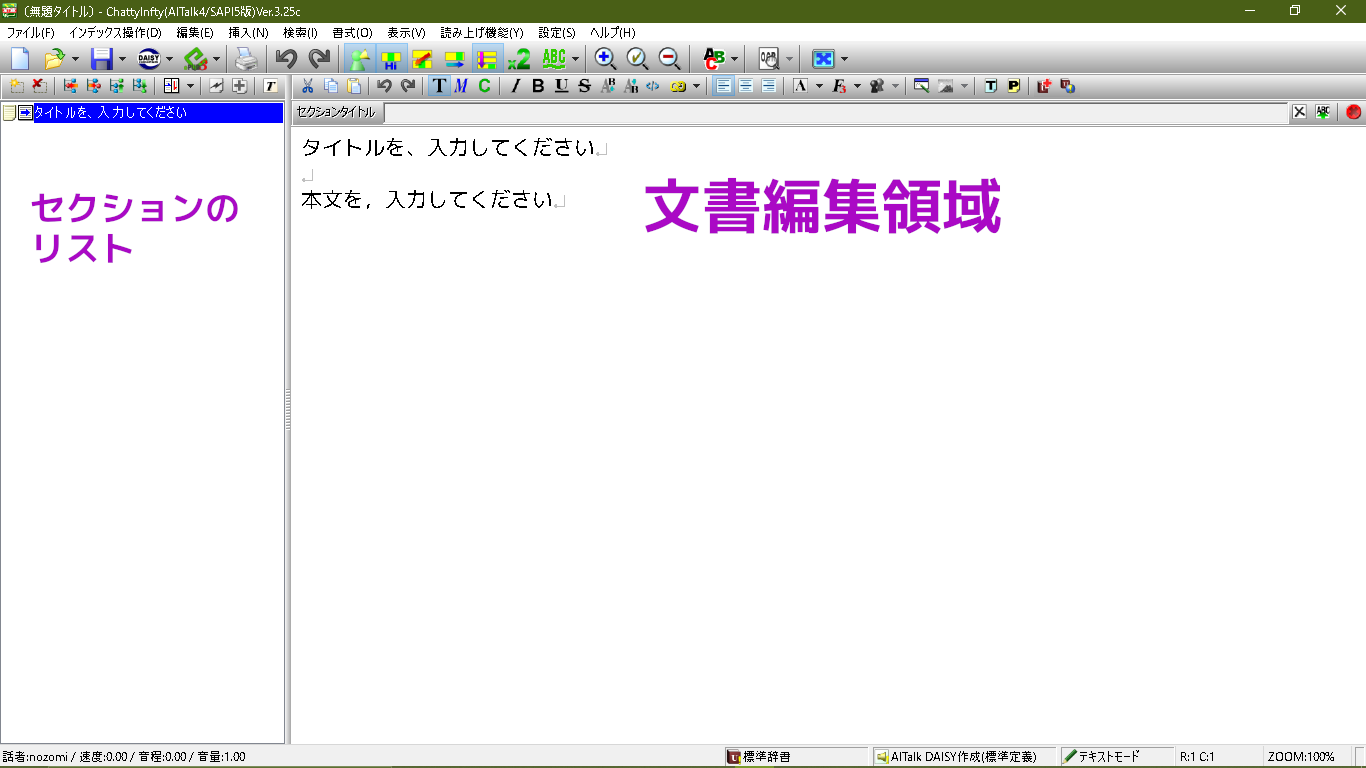
文字を大きく表示したいときはメニュー下の右寄りにある+アイコンをクリックする。これは編集画面での表示だけを拡大し、デイジー図書の完成品には影響しない。
デフォルト設定の表示フォントは教科書体なので、半角全角の区別や数字とアルファベットの区別などがわかりにくい。表示フォントを変更したいときは「設定>オプション設定」の「フォント」タブで変更することができ、サイズも大きめのものを選ぶことができる。このフォント設定もデイジー図書の完成品には影響しない。
おすすめのフォントは Migu 1M である。このフォントをあらかじめ Windows にインストールしておけば、 Chatty 起動後に上記の設定画面で Migu 1M を選択できる。
3.2. テキストをインポートする
ChattyInfty3 では テキストファイル *.txt か EPUB3 形式のファイル *.epub をインポートして編集できる。この方法を使うと、ルビ設定のあるテキストをルビ付きのままインポートできる。
テキストファイルの場合は、メニューの「ファイル>インポート>File Import」を選ぶ。複数のテキストファイルを一度にインポートでき、ファイルごとに別セクションになる。右下の3つのチェックボックスはオフにする。
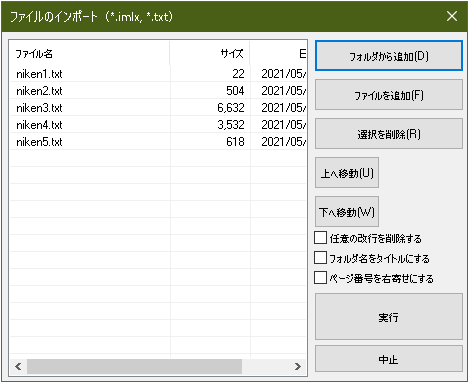
テキストのルビが以下の形式で書かれていれば、テキストインポート後の編集画面では、すでにルビ設定ができた状態になっている。
- テキストの記述:
-
一度|浅間《あさま》の爆発を - Chatty 編集画面の表示:

音声デイジー製作の場合は、ルビが付いていても構わないが、無くても良い。ルビは読み上げに一切影響しない。 本文の漢字の読みが、ルビの形にならずに本文中にひらがなで挿入されてしまうと、それを手で消さないといけないのでとても煩わしい。 正しいルビ形式でインポートできないなら、テキスト修正の段階ですべてのルビを消すほうがマシである。
マルチメディアデイジー製作の場合はルビが必要な場合もある。全ての漢字にルビを付けた場合は、 WCAG の 3.1.6: Pronunciation AAA要件の一つを満たすことになる。Chattyでは全ルビ変換のプラグインを使って自動的にルビを付けられる。
特殊な読みの場合や、自動ルビの間違いを修正する場合は、ルビ設定 Ctrl Shift ↑(上向き矢印キー) を使って手動でルビを付ける。
ルビを付ける範囲が間違っているときは、ルビ設定画面でそのルビを削除して適用すると、ルビ範囲を選び直すことができる。
ChattyInfty3 の EPUB インポート機能は完全ではなく、失敗したり欠けたりすることもある。元の EPUB ファイルの構造を少し変更して作り直したものをインポートすると成功することもある。 どういう場合に成功するかは、その都度試行錯誤してみないとわからない(2021年5月8日時点)。
3.3. 音訳処理
音声デイジーだけを製作する場合、セクションタイトルになる行の文字列だけは製品に含まれるので、その行は原本どおりの表記にする。それ以外の本文の文字列は、デイジー製品に含まれないので、図表・グラフ・漢字などの説明文を本文中に自由に書き込んで良い。
マルチメディアデイジーも製作する予定がある場合は、原本文字列を絶対に改変してはいけない。音訳者注には〔全角亀甲括弧〕や{全角中括弧}など、原本で使われていない種類の記号を付けて区別し、その事をデイジー図書凡例で言う。
3.4. 読み上げの調整
3.4.0. 読み上げに異常がある場合
原本となるテキスト原稿には、一見問題無さそうに見えるのに、読み上げさせると異常な読み上げになるものが存在する。
例えば pdf などで原稿を受け取った場合、原稿内に AITalk などの読み上げエンジンが扱えない文字が多数含まれていることがある。この原因は、見た目はそっくりでもコンピュータにとっては全く違う文字が存在するからである。
- 読み上げエンジンが扱えない文字(例文出典:『ぽけっと7月 北区図書館情報』刊行物登録番号 2-2-125, 北区立中央図書館, 2021. pdfファイル.):
この場合は、コンピュータにとって読み上げ可能な文字に変換してから Chatty に取り込む必要がある。その方法の1つとして、以下の方法が簡単である。読み上げられない文字を手作業で修正するのはヒューマン・エラーを増やす可能性があるので、できるだけ避ける。
- pdf などの原稿から
Ctrl AとCtrl Cなどの方法で文字列をコピーする。 - それを以下のウェブページで
Ctrl Vなどの方法で貼り付ける。
Unicode正規化 (NFC, NFKC, NFD, NFKD) 変換 Online - 貼り付けると下に結果が出て、その中に「エンコード結果 正規化(互換)」という欄がある。その行をクリックする。
- クリックするとその行の上下幅が広がり、右端に「コピー」のアイコンが出る。それをクリックする。
- Chatty の編集画面で
Ctrl Vなどの方法で貼り付けする。
以上の方法で変換したものは正常に読み上げられる。ただし、「☎(電話マーク)」や「〜(波ダッシュ)」などは無理。
- 「☎(電話マーク)」は、後述する「読み設定」機能を使って「電話」などの読みを当てると良い。
音声デイジーだけを製作する場合は、本文文字列がデイジー製品に含まれないので、この記号自体を「電話」という文字に置き換えて読み上げさせても著作者人格権を侵害しない。 - 「〜(波ダッシュ)」が「から」の意味で使われている場合は、「~(全角チルダ)」に置き換えれば「から」と読み上げる。
3.4.1. AITalk の音声のバリエーション
ChattyInfty3 AITalk版では「せいじ」「のぞみ」「かほ」の3人の音声が利用できる。
音声合成エンジン AITalk を製造している株式会社エーアイは、他にも多くの種類の音声を作っていて、サンプルを聴き比べることができる。
読み上げ機能に関するアイコンは、メニュー下の中央あたりに並んでいる。

アイコンにマウスカーソルを乗せると機能の説明がポップアップされる。
よく使う機能にはショートカットキーもある。
例えば、読み上げのオン・オフは Alt R 、自動読み上げ(次の行も続けて読む)のオン・オフは Alt A である。
読み上げ方には個性があるので、ある音声の読み上げで気になる点があれば、別の音声に変えても良い。 メニューの「設定>音声設定」で、標準話者を選択でき、音量なども変更できる。
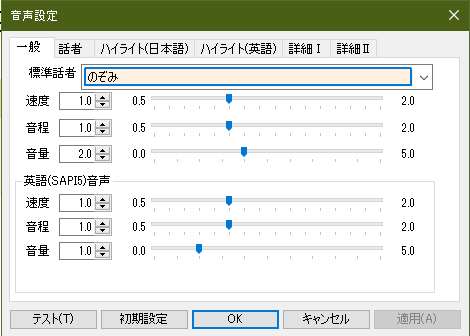
この音声設定内容は、編集画面だけでなく、デイジー図書の完成品にも反映される。 デイジー図書の音量のピークが -12dB から -6dB の間に入る程度にするには、のぞみの音量なら 2.0、せいじの音量なら 1.5 程度がちょうど良い。 英語音声も種類により音量が異なるので、編集画面で特定の英語音声に英語を読み上げさせ、標準話者の音量とのバランスによって英語音声の音量を調節する。
編集画面は基本的に、標準話者として選択した日本語音声で読み上げられる。
英語の文章を英語音声で読み上げさせるには、英語の文章を選択して Ctrl Shift V または右クリックで話者切り替えをする。
- 音声のバリエーション:
日本語 AITalk の音声は、 ChattyInfty3 や音声辞書の更新によって読み上げ方が変わることがある。 そのため、1つのプロジェクトに一緒に関わる Chatty ファイル作成者と校正者は、必ず同じバージョンを使わなければいけない。
英語以外の外国語を ChattyInfty3 SAPI5 版で読み上げさせる方法の概略は後述する。
3.4.2. スペース・ポーズ・ハイライト分割の作用
スペースを入れることによって、日本語の構文上の区切りを読み上げエンジン AITalk に教えることができる。スペースを入れると、その直後のプロミネンスが立つことが多い。
- スペースとショートポーズの違い:
スペースは必ずしもポーズにならない。 AITalk が構文解析をした結果、そのスペースの位置にポーズを入れるのが妥当であると判断した場合はポーズになる。
もともと自然にポーズが入っているところにスペースを入れても、ポーズが長くなることはない。
ただし、音声設定で、連続したスペースをハイライト分割に設定してある場合は、そのせいでスペース2個がポーズになる。
ショートポーズ Ctrl Shift S やロングポーズ Ctrl Shift L は、どこに入れても入れた個数だけ長いポーズができる。
行末にポーズを入れたいときは句点などの記号の直前に入れる。 記号の後にいれると、そのポーズだけで無音のフレーズを構成してしまうので、デイジー図書としての出来が悪くなる。

構文解析による自然なポーズ、強制的に入れるショートポーズやロングポーズのほか、読点や句点、改行などでもポーズが入る。 それぞれのポーズの長さを、デイジーエクスポートした音声ファイルで測定してみると、短い方から以下の表に示した順番で長くなる(測定値なので誤差はある)。
ここに示したポーズの長さはデイジー図書の完成品に反映される長さであり、編集画面で聞こえてくるポーズの長さと必ずしも一致しない。 これは、編集画面では特に改行のポーズの長さがパソコンの処理速度に依存するせいである。
- 表:ポーズの長さの比較
-
ショートボーズ Ctrl Shift S171 ms ロングポーズ Ctrl Shift L365 ms ハイライト分割しない設定にした読点「、」 385 ms ハイライト分割 Ctrl Shift /517 ms 読点「、」 517 ms ハイライト分割しない設定にした句点「。」 800 ms 改行 1015 ms 句点「。」 1315 ms セクション末 2161 ms
デフォルト設定では読点・句点・改行でハイライトも切れる。
ハイライト分割 Ctrl Shift / は、ポーズを入れるとともに、構文上の区切りを AITalk に教える。 つまり、読み上げに対してスペースの機能とポーズの機能を併せ持つ作用がある。
ハイライトを区切りながらもポーズを追加したくない場合は、ポーズ無しのハイライト分割 Alt Ctrl Shift / を使うと良い。これはスペースと同様に、構文上の区切りを AITalk に教える機能だけを持ち、その直後のプロミネンスが立つことが多い。 AITalk がここをポーズにすべきと判断すればポーズになるし、そうでなければポーズにならない。
デフォルト設定では読点でハイライト分割になるが、音訳講習でよく指摘されるとおり、フレーズの切れ目として適切ではないところにも読点は出現する。 そこでフレーズを切って良いかどうかを判断をするためには文の意味を理解する必要がある。それは AITalk にできない仕事なので、人間が読解してフレーズの切れ目を調整しなければならない。
音訳者として切るべきではないところに読点がある場合、対処法は3種類ある。
- 切りたくない読点の後にハイライト結合
Ctrl Shift +を入れる。ポーズが消えるわけではないが、直後のプロミネンスが弱くなる。 - その読点を無音範囲
Ctrl 0に設定する。場合により、無音設定の直後にスペースを入れて読みを調整する必要がある。 - 「設定>音声設定」の「ハイライト(日本語)」タブで「読点で分割」のチェックボックスをオフにする。読点で切るべき場合も多いので、おすすめしない。
- 切りたくない読点(例文出典:北区障害者計画2021):
3.4.3. 日本語のアクセント規則
ChattyInfty3 AITalk版の単語登録機能を使って、デイジー図書の利用者に意味が伝わる読み上げを作るためには、以下のような日本語のアクセント規則を念頭に置いて作業する必要がある。
ここでは標準的日本語のアクセント規則だけを説明する。方言には言及しない。
日本語には高低アクセントがある。音の高さは、1つの拍 (mora) に対して高低どちらか1つが決まる。高い拍が連続したり、低い拍が連続したりすることもある。

日本語の音声を細かく区切ろうとするとき、意味が通じる最小単位を文節と呼ぶ。「ね」を挟んでも通じるところが文節の切れ目だと教える人もいる。
- 例
- 大きな地震が来たらエレベータの代わりに非常階段を使う。
- 大きなね 地震がね 来たらね エレベータのね 代わりにね 非常階段をね 使うね。
1つの文節は、高い拍で始まると、2番めの拍は必ず低くなる。低い拍で始まると、2番めの拍は必ず高くなる。
1つの文節の中では、高い拍が複数ある場合でも、高い拍は必ず連続している。1つの文節の中で、高い拍が低い拍の谷を挟んで2つの山に分かれることはない。 逆に言えば、日本語を聞いて意味を理解しようとするとき、高い拍の位置を頼りにすれば、文節がどこで切れるかをある程度把握できる。 聞こえてくる日本語の音声に高い拍の山が2つあれば、その音声は少なくとも2つの文節からできているはずである。
高い拍のまとまりの最後の拍、つまり低くなる直前の拍を「アクセント核」と呼ぶ。
文中では名詞の後に助詞が付くことがあり、その名詞と助詞はまとめて1つの文節を構成する。 その文節内の名詞は、アクセントの特徴に基づいて以下のような分類をされることもある。
- 名詞の最初の拍にアクセント核があると頭高型
- 名詞の最初と最後の間の拍にアクセント核があると中高型
- 名詞の最後の拍にアクセント核があると尾高型
- 名詞内にはアクセント核が無い、つまり次の助詞の最初の拍が下がらないと平板型
新明解国語辞典のアクセント記号は、アクセント核がその単語の何番目の拍にあるかを四角囲みの数字で表している。四角囲みの0は、その単語にアクセント核が無い、つまり平板型であるということを表す。
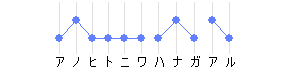
- 花:アクセント核2、いわゆる尾高型
-
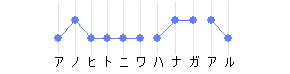
- 鼻:アクセント核0、いわゆる平板型
-
名詞が1拍だけでできている場合、その名詞よりも次の助詞のほうが高くなれば、その名詞にはアクセント核が無い、つまり平板型と見なされる。
次の助詞のほうが低くなれば、その名詞自体がアクセント核である。これを頭高型と呼ぶのは構わないが、そもそも1拍しか無いので頭か尾かの区別は無意味である。
- 気:アクセント核0、いわゆる平板型
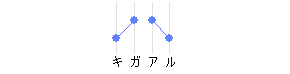
-
- 木:アクセント核1、それ自体がアクセント核
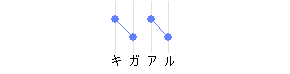
-
促音(つまる音)を含む単語で、促音の前後で高さが変わる場合、促音自体の拍はその直後の拍と同じ高さと見なされる。つまり促音の拍はアクセント核になり得ない。
- リュックサック:アクセント核4、「サ」がアクセント核
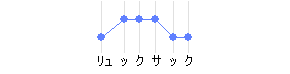
-
名詞の連続や動詞の連続が複合語と見なされているかどうかは、高い拍の位置によってある程度把握できる。 2つの単語が隣り合って複合語と見なされる場合は、複合語内部では文節が切れず、複合語内部で高い拍の山が2つに分かれないようにアクセントが変化する。
- 複合名詞

-
- 複合動詞
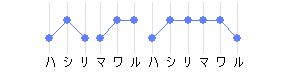
-
3.4.4. 単語登録
単語の読み方やアクセントが間違っているとき、その単語を「単語登録」することによって修正できる。 1回単語を登録しておけば、その単語がどの文脈にあっても、その都度 AITalk が適切なアクセントやイントネーションを判断し、自然な読み上げを作る。 ただし単語登録のしかたが不適切だと、かえって奇妙な読み上げになる。
単語登録をするには、アクセントを登録したい単語を選択した状態で Ctrl J を押す。読み方をカタカナで指定してから、アクセントを表す丸い印をマウスで動かす。
この図書の中で他の読み方がありえないなら、優先度を「高」にして良い。
- 単語登録 GAFAM:
単語登録したい文字列を複数の文節に分けたい場合もある。単語登録の範囲内で分節を分けるには、アクセントの丸い印を右クリックして切断する。 これを切断しなかったり、不適切なところで切断したりすると、まったく思い通りのアクセントは作れない。
- 単語登録 東京特許許可局:
ChattyInfty3 に付属している AITalk は、単体で売られている AITalk と違って、登録できる単語の品詞が限られている。名詞と記号だけを登録でき、動詞や形容詞などは登録できない。 動詞や形容詞などを名詞として登録してしまうと、前後の文脈の中で名詞としてのアクセント変化が起き、読み上げが不自然になるし、活用形にも対応できない。
そういう品詞のアクセントを変更したい場合、特定の名詞句の内部に現れるだけなら、その名詞句全体を名詞として単語登録すればよい。 それ以外の場合は、後述の読み設定で調整する。
- 単語登録 エモい歌詞:
単語登録で、名詞の最後の拍を高くすると、普通は平板型として登録される。つまり文中の読み上げではその名詞の次の助詞が高い拍で始まる。
- 単語登録 エモい山脈:
ただし、1つの拍だけからなる名詞を高い拍として単語登録すると、その名詞の拍はアクセント核と見なされ、文中の読み上げでは次の助詞が低い拍になる。 逆に、その名詞を低い拍として単語登録すると、その名詞にはアクセント核が無いものと見なされ、次の助詞は高い拍で始まる。
単語登録機能のこの性質を応用すると、複数の拍からなる名詞でも、尾高型として登録することが可能になる。つまり、登録語句の最後の単語を尾高型にするには、その単語の最後の1拍を切り離し、単独の高い拍であるかのように見せかけて登録すれば良い。
- 単語登録 エモい山:
単語登録では、名詞の種類を細かく指定できる。これをできるだけ正確に指定すれば、 AITalk は前後の文脈の中で比較的適切なアクセントを判断してくれる。
例えば、地名を「名詞 一般」として単語登録すると、他の地名の後に付くときにアクセントが消えてしまうが、「名詞 固有名詞 地域 一般」として単語登録すると、文脈の中で適切なアクセントになる。
- 単語登録の名詞の種類:
3.4.5. 読み設定
スペースやポーズ、単語登録などで読み上げが修正できないとき、最終手段として読み設定機能 Ctrl Shift ↓(下向き矢印キー) を使う。
読み設定の基本的な使い方
基本的な読み設定の方法では、アクセント制御をする。 そのとき、読み設定の範囲として、直したい部分だけではなく、その前後でフレーズを切っても良さそうな範囲を選択する。
なぜなら、 AITalk はフレーズ単位で構文解析してイントネーションを調節しているが、アクセント制御をオンにして読み設定した範囲内は構文解析しないので、フレーズより小さい範囲に読み設定すると、その前後とのつながりが AITalk にわからず、不自然な読み上げになるからである。
読み設定画面で、「アクセント制御」チェックボックスをオンにしたまま、カタカナと記号を以下の規則で書き込んで読み方を指定する。
- 読みをカタカナで書く。
- 発音上、長音になる位置には、母音のカタカナを書かずに長音記号を使う。
- 文節の切断には全角アンダーラインを入れる。
- アクセント核の直後に全角アポストロフィを入れる。
- 読み設定の基本:
読み設定の便利な使い方
上記の方法で設定すると、 AITalk がこの設定範囲内を構文解析しないため、前後の文脈との構文上のつながりが把握できず、読み上げが不自然になる場合がある。
これを避けるために、 AITalk の構文解析能力を活かしたまま読み設定をする方法もある。 読み設定の「アクセント制御」チェックボックスをオフにして、読み替えを普通の漢字かな交じり表記で記入する。 こうすると、 AITalk は前後の文脈の間に読み替え部分を挿入した形で構文解析するので、自然な読み上げに仕上がる。
- 読み設定の便利な使い方(例文出典:渡辺 温『遺書に就て』青空文庫.):
ここでは読み設定の説明のため、「遺書」を「カキオキ」と読ませることに読み設定を使ったが、「遺書」は名詞として使われているので、その文書全体で常に「カキオキ」と読むのであれば、単語登録で読みを修正する方が簡単である。
フレーズに音声ファイルを当てる
読み設定機能を使って、他のアプリ等で作成した音声ファイルを、フレーズ単位で当てはめることができる。
- AITalk版では読み上げられない文字列に、音声ファイルを当てる:
他に、 NEUTRINO などで歌わせて作成した音声ファイルや、自分の声の録音ファイルなども当てはめることができる。音訳以外の用途に使う場合は、音楽や効果音も入れることができる。
3.4.6. 外国語
英語以外の言語を正しく読み上げさせるには、 ChattyInfty3 SAPI5版や、他の読み上げエンジンを使う。
AITalk版ライセンスを購入していれば SAPI5版も使えるはずであるが、最近のバージョンでは SAPI5版においてライセンスが認識されないという不具合がある(ver.3.25c 時点)。それでも、のべ30日はすべての機能を利用できる。
SAPI5版メニューの「設定>音声設定」では、Windowsにインストールされているすべての音声から、テキストの音声を選択できる。 AITalk版と同様の方法で、一部分だけ他の音声に変更することもできる。
読み設定で読み方を変更することもできる。単語登録機能はない。
日本語の図書の一部分だけを英語以外の外国語で読み上げさせる場合は、 SAPI5版で作成した読み上げ音声をデイジーエクスポートして、上記の「フレーズに音声ファイルを当てる」方法でその音声ファイルを指定することにより、フレーズごとに外国語音声を当てはめることが可能である。
3.4.7. 数式
ChattyInfty3 のデフォルトの入力モードはテキストモードになっている。
数式モード Ctrl M で書き込むと、その部分を数式として読み上げる。
テキストモードに戻すには Ctrl T を押す。
(同様の方法で化学式モード Ctrl K も利用できるがここでは説明しない。)
文の途中に出てくる短い数式や数学記号も、アクセシビリティの観点と美観の両方から考えて、数式モードで書くべきである。
すでにテキストモードで入力されている数式は、その部分を選択して Ctrl M を押せば、数式モードに変更できる。
特殊な記号は LaTeX (ラテフ)コマンドで書き込める。
数式入力モードで \ (バックスラッシュまたは半角円記号)で始まる LaTeX コマンドを入力していくと、コマンド候補のリストが現れるので、そこから目的のものを選択しても良い。
数式モードの使い方の詳細はメニューの「ヘルプ>入力説明」に書かれている。
数式モードであっても、その読み上げは音訳として正しくない。「設定>読み上げ定義の編集」である程度修正できそうではある。これをいじらない場合は、以下の例のような音訳的読み替えを手動で記述し、数式に当てるという方法が考えられる。
- 数式(例文出典:西成 活裕『東大の先生! 文系の私に超わかりやすく数学を教えてください!』かんき出版, 2019.):
LaTeX 原稿の取り込み
もとのテキストが LaTeX で書かれているなら、以下の方法によってある程度、 *.tex ファイルから、Chatty上での数式表示を得ることができる。
まず、テキストエディタ等で *.tex ファイルを開く。そこで LaTeX コマンドを含むテキストをコピーし、 Chatty の編集画面でペーストする。ペーストされた部分は自動的に数式モードになり、 *.tex ファイル内の LaTeX コマンドで指定したとおりの数式が表示される。
*.tex ファイル内のテキスト例:
$ \hat{H} | \psi_n (t) \rangle = i \hbar \frac{\partial}{\partial t} | \psi_n (t) \rangle $
- Chatty編集画面にコピー&ペーストした状態:
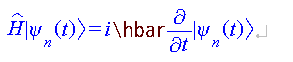
数式化に失敗している \hbar の部分を、Chatty 編集画面上で消して、そこに \hbar をタイピングで入力すると、正しい表示が選択肢に出るので、それを選択すれば修正できる。
- 修正された状態:
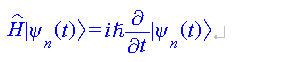
以上のように数式を LaTeX コマンドで直接取り込む機能は、コピー&ペーストの操作によって利用できるが、 File Import では利用できない。
逆に言えば、数式のつもりではないテキスト原稿を、コピー&ペーストで Chatty 編集画面に取り込むと、そのテキスト内に Chatty が数式と判断する文字が含まれていれば、意図したとおりには表示されない。 テキストを原稿どおりの表示で利用したいならば、メニューから「ファイル>インポート> File Import」によって取り込む必要がある。
3.5. フレーズの結合
ハイライト結合 Ctrl Shift + は、句点や括弧などで自動的にフレーズが切れるように設定してある場合に、その箇所だけ切らないでつなげたいときに使う。
- 例えば「設定>音声設定」で、括弧はじめの前でフレーズが切れるように設定している場合:
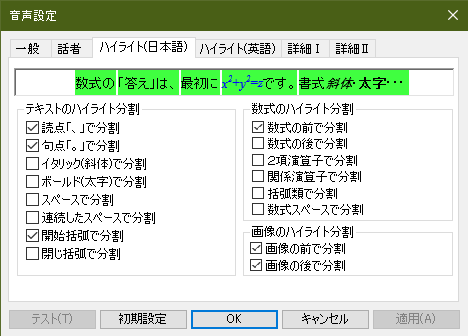
この設定では、曜日が括弧で表されているところもフレーズが切れる。その前の日付けとつなげて読み上げさせるには、括弧はじめの前でハイライト結合をする。
- 日付と曜日のハイライト結合:
ある部分を選択してフレーズ結合 Ctrl * すると、選択した部分の中ではハイライトが切れず、選択した部分の直前直後がハイライト分割になる。
読点や括弧が含まれるセクションタイトルを1フレーズにしたいときに使える。
- セクションタイトルのフレーズ結合:
3.6. コメントの挿入
以下の形式で、デイジーデータに影響しないコメントを入れることができる。この方法は、校正や自分用のメモなどに使うことができる。
コメントを適切な場所に書き込めば、最終的に消さなくても、完成したデイジーデータでは見栄えや読み上げに一切影響しない。 実はマルチメディアデイジーの場合には技術者にしか見えない形でデータ内に含まれているが、音声デイジーの場合には、セクションタイトル内にコメントを入れない限り、データ内には全く入らない。
マルチメディアデイジーの場合は、利用上の影響はないものの、データには含まれてしまうので、エクスポートする前にコメントを消すほうが良い。一度に全部消すには、自分でスクリプトを書いてimlxファイルから自動的に消す。
コメントを入れてもデイジーデータに影響しない場所は、セクションタイトル以外の以下の場所に限られる。
- ハイライトとハイライトの隙間
- 行頭・行末
- 独立した行
まず、編集画面の文中のコメントを入れたい場所に、以下のように !-- と -- でコメントを挟む形式で書き込む。
本文、本文、!--これはコメントです。--本文、本文。!--これもコメントです。--↵
!--こっちもコメントです。--↵
次に、 !-- から -- までをマウスや Shift 矢印キー などで選択し、HTMLタグモードのアイコンをクリックする。
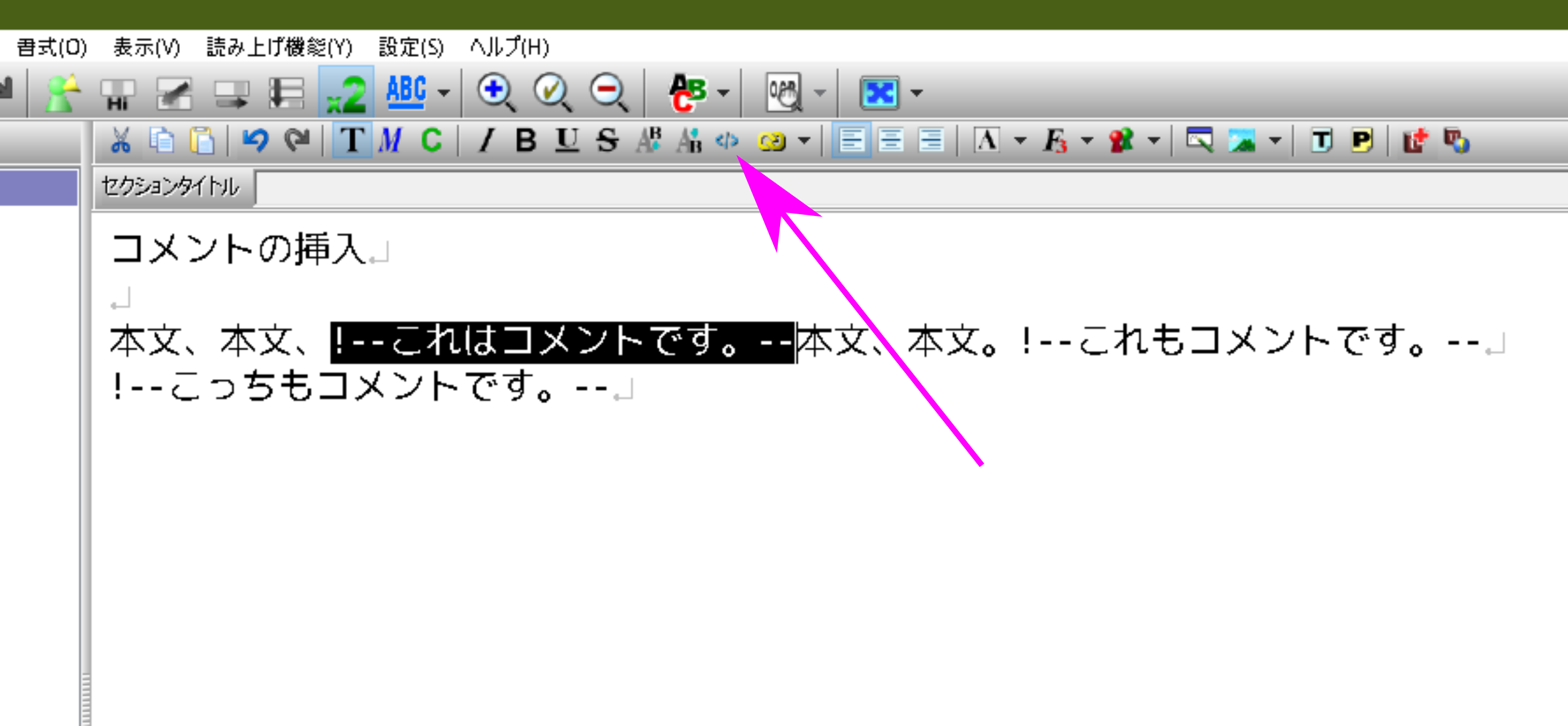
コメント化された部分は水色になる。
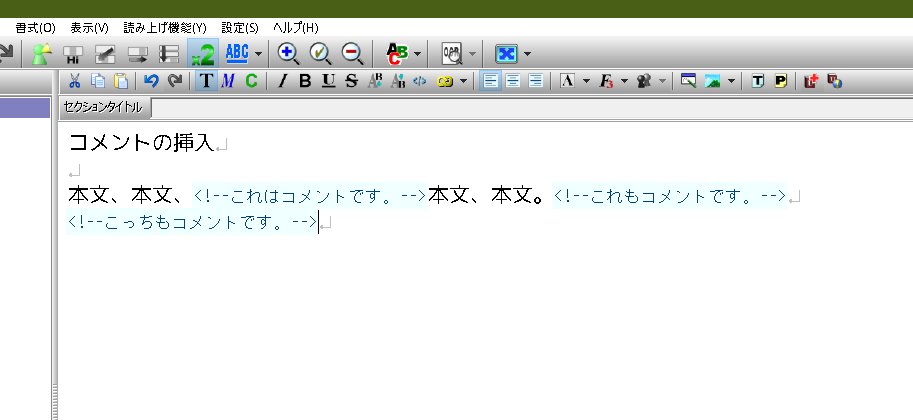
実は、音声デイジーの場合に限り、 !-- と -- で挟まなくても、コメント文をHTMLタグモードにするだけで、デイジーデータに影響しないコメントを付けられる。
3.7. 複数の Chatty ファイルの統合
1つの図書を複数の人員で分配して部分ごとに Chatty ファイルを編集した場合、ある段階で Chatty ファイルを統合する必要がある。
メニューの「ファイル>追加読み込み」で、複数の *.imlx ファイルを1つのファイルに統合することができる。
ただしこれだけでは追加した部分の単語登録が反映されていない。
複数の *.imlx ファイルに登録された単語を反映させるには、「設定>単語辞書をインポート」機能を使う。
この機能を開くと、「インポートするドキュメントを選択」ウィンドウが出るので、他の人が作った *.imlx ファイルを選択する。
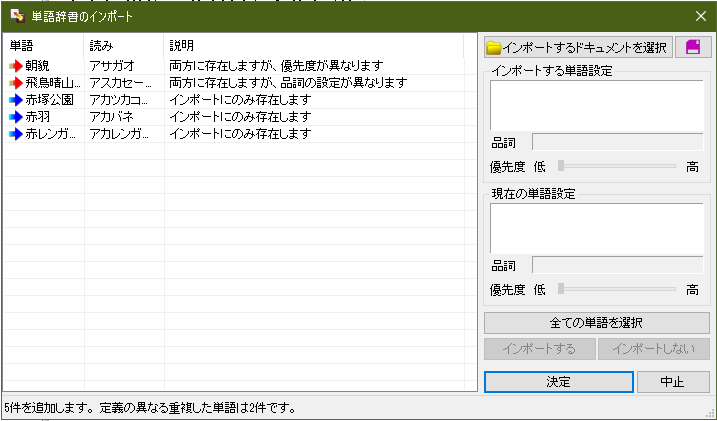
各単語の左に付いている青や赤の矢印は、その単語をインポートするという意味である。 青い方は、自分の Chatty ファイルに登録されていない単語、 赤い方は自分の単語設定がその人と違う単語である。
単語を1つ選んで「インポートしない」ボタンをクリックすると、青や赤の矢印が灰色に変わり、その単語をインポートしないことになる。
そのファイルを作った人の単語設定を信用している場合は、すべての単語が青や赤の矢印になっている状態で「決定」ボタンをクリックする。 そうでもない場合は、1個ずつの単語設定を見ながらインポートするかしないかを選んでから、最後に「決定」ボタンをクリックする。
1個ずつ単語設定を検討しないですべてインポートする場合は、最も信用しているファイルの単語辞書を最後にインポートすれば、重複する単語設定すべてを、信用しているほうの設定で上書きできる。
3.8. セクションやページ番号の操作
3.8.1. セクション
セクションの個数が多いほど、文書全体の検索置換処理が遅くなる。 一方、1セクション内の文字数が多いほど、セクションを編集画面に表示する処理が遅くなる。
検索置換することが多い作業の場合は、総合的に考えると、セクション分割をなるべく編集作業の終盤でするほうが良い。
セクションを分割するには、新セクションのタイトルになる行で Alt Enter を押す。
メイン画面の左のセクションリストの上にはセクション操作のアイコンが並んでいる。これを使ってセクションの前後移動やレベルの上下もできる。
編集画面の1行目(1行目が空行やページ設定行などの場合は、空行やページ設定行などではない最初の行)は自動的にセクションタイトルになる。
編集画面の上にある「セクションタイトル」欄に記入すると、「セクションタイトル」欄の内容が目次に載り、編集画面1行目の内容がそのセクション内のページに見出しとして表示される。 この方法を使うと、目次と見出しが一致しないデイジー図書も作れてしまう。
WCAG の 2.4.10 Section Headings (Level AAA) の観点から考えると、少なくともマルチメディアデイジーの製作ではこの方法を避けるべきである。音声デイジーの場合、全国基準の参考例を適用するなら、「著作権ガイド」と「終わりアナウンス」をセクションタイトルに書き、それを読み上げないことになる。
3.8.2. ページ番号
音声デイジーだけを製作する場合
ChattyInfty3 のページ番号機能は貧弱なので、音声デイジーだけを製作する場合は PRSPro で自動的にページ番号を付けるほうが簡単である。
まず Chatty 上では、改ページして最初に始まるフレーズの 直後 に空行を入れてページ番号位置を設定 Alt P しておく。
間違えて設定した場合はもう一度 Alt P するとページ番号位置の設定が消える。
ページ番号以外の編集が完了したら、デイジー2.02 マルチメディアとしてエクスポートし、そのデータを PRSPro でDAISYインポートして、 PRSPro の機能でページ番号を自動的に付けてもらう。
DAISY2.02 音声のみの方をエクスポートしないのは、 DAISY2.02 音声のみの出力データを他のアプリでインポートする際に不具合があった経験が何回かあり、この機能をあまり信用していないから。
PRSPro では、Ctrl 下向き矢印キーで、ページ番号の付いたフレーズに飛び、そのフレーズは無音なので削除し、直前にあるフレーズにPキーでページを付ける。
マルチメディアデイジーも製作する場合
音声デイジーのためのページ付け方法は、マルチメディアデイジーでは正しい形に直しにくいので、マルチメディアデイジーと音声デイジーの療法を製作するときには、ページをめくって最初に始まるフレーズの 直前 にページ番号行を作る。
3.9. デイジー図書のエクスポート
3.9.1. 音声デイジー
以下の条件をすべて満たしているときは、 Chattyメニューの「ファイル>DAISY出力」の出力形式「DAISY 2.02(音声のみ), mp3 64 kbps, エンコード utf-8」で出力し、それを Shift_JIS に変換することによって、音声デイジーを作成できる。
- 外部音声ファイルを当てていない。
外部音声ファイルを当てていると、 Chatty から出力した音声デイジーを ChattyBooks で再生する際にセクション抜けの不具合が出るため(2021年2月25日現在、sAccessNetに報告済)。
- ページ番号が必要な場合、ページをめくって最初に始まるフレーズの直前に、正しいページ番号付きで設定をしてあり、この部分が1秒の無音フレーズになることを厭わない(この点で全国基準に違反することが許される場合)。
- 自分で
discinfo.htmlを作成する能力がある。 - 出力されたデイジーデータのすべての
UTF-8テキストをShift_JISテキストに変換し、それに応じて各ファイル内のエンコーディング指定も正しく書き換える能力がある。
Chatty から Shift_JIS で出力せずに、 UTF-8 で出力してから別の手段で Shift_JIS に変換するのは、文中に1文字でも Shift_JIS に含まれない文字が書かれていると、DAISY 2.02 (音声のみ)のエクスポートデータに UTF-8 と Shift_JIS が混在し、正しくないデータとなるため。(2021年2月25日現在、sAccessNetに報告済)。
discinfo.html は以下の形式のテキストファイルであり、Shift_JIS エンコーディングで保存する。
CDなどの媒体にデイジーデータを書き込むとき、最上位の階層に、デイジーデータが入っているフォルダと並ぶ形で discinfo.html を入れる必要がある。
discinfo.html:
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title>CD Information</title>
<meta http-equiv="Content-type" content="text/html; charset=Shift_JIS"/>
</head>
<body>
<a href="./デイジーデータが入っているフォルダ名/ncc.html">ここに書名を入れる</a>
</body>
</html>
上の条件のどれかを満たしていない場合は、Chatty から出力形式「DAISY 2.02 (マルチメディア)」として出力したデータを、PRSPro からDAISYインポートして仕上げの作業をする。
完成品は必ず PTN2 や AMIS などで正常に再生できるか確認する。
3.9.2. マルチメディアデイジー
現在使われている音声付き電子書籍として、 DAISY 2.02 と EPUB3 がある。
Chattyメニューの「ファイル>EPUB出力」の出力形式「EPUB(音声あり)」によって、 EPUB3 with Media Overlays 形式のマルチメディアデイジーを作成できる。
ただし、これによって作られる epub ファイルは WCAG を考慮しない作りになっているので、アクセシブルな電子書籍にするためには多少の改変が必要である。詳しい方法はマルチメディアデイジー制作のための理論と実践を参照。